LLM Limitations
LLMs are powerful tools, but they have inherent limitations that impact the accuracy and reliability of their generated content—including code. Understanding these limitations will help you critically evaluate their outputs and ensure high-quality data analysis.
⚠️ Limitations and What to Watch Out For
LLMs generate code by predicting what a correct answer might look like, not by understanding your data or testing their output. That means they are:
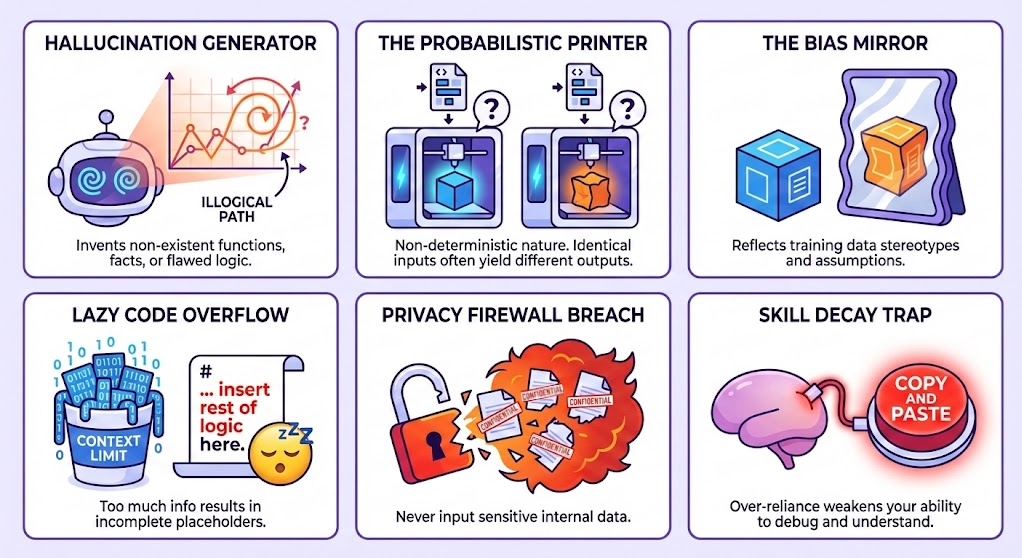
1. ❌ Prone to Hallucination
They may:
- Suggest functions or methods that don’t exist (e.g., made-up Pandas or Matplotlib functions)
- Give you almost-correct code that doesn’t run
- Contain logical errors that produce incorrect analysis results
- Include incorrect facts about your data or domain
🔍 Always read, test, and validate LLM output before using it in your analysis.
2. 🤨 Inconsistent Responses
Sometimes the LLM might respond with:
“I’m sorry, I can’t do that…”
…even when you know it can! This happens because:
- LLMs are probabilistic — they don’t always respond the same way
- Slight changes in wording or rerunning the prompt can produce better or worse results
3. 😴 Lazy Code and Incomplete Responses
Sometimes the LLM will generate code with placeholders like:
# ... rest of logic remains the same
# ... insert previous code here
# ... (keep existing code)This is a problem! If you copy and paste this code directly, your program will break because these aren’t real Python comments — they’re placeholders the LLM used to avoid generating the full file again.
This “lazy code” typically happens when:
- The request is too large — You’re asking the LLM to generate or modify a large file, which exceeds its practical output limits
- The context is too broad — The LLM has too much information and tries to shortcut by only showing changes
- The problem isn’t decomposed — You’re asking for everything at once instead of breaking it into smaller, manageable pieces
We go into methods of reducing this lazy code in prompting techniques.
4. ⚖️ Bias in Responses
Because LLMs are trained on large datasets, they can reflect:
- Cultural, social, or technical biases
- Stereotypes or outdated practices
- Assumptions about data that may not apply to your context
It’s your job as a responsible data analyst to critically evaluate the output, just as you would with code from Stack Overflow or GitHub.
5. 🕵️ Data Privacy and Confidentiality
LLMs may retain or use input data. When working with datasets, it’s crucial to protect sensitive information. We’ll cover comprehensive data privacy strategies and best practices in the Practicing Responsible AI section of this module.
6. 🧠 Over-Reliance and Skill Decay
LLMs are great helpers, but they’re not a replacement for your own thinking.
As a data analyst, you still need to be able to:
- Understand and explain your analysis approach
- Debug code from scratch
- Validate results using domain knowledge
- Make informed decisions about data cleaning and transformation
- Communicate findings to stakeholders
The best data analysts will be those who know how and when to use AI—see Principle 3: Use AI as a Learning Tool.
AI Limitation Overview
✅ What to Look For When Using LLMs
| Area | What to Check |
|---|---|
| Correctness | Does the code run and produce the right result? |
| Data Validity | Are the transformations and calculations correct? |
| Clarity | Is the code readable and well-structured? |
| Bias | Are there assumptions or stereotypes in the analysis approach? |
| Domain Knowledge | Does the result make sense in real-world context? |
| Consistency | Is the output reproducible, or does it change on rerun? |
| Privacy | Are you exposing any sensitive data in the prompt? |
Next, we’ll learn how to write effective prompts to make the most of these tools.